Pojmovnik
- Afrilex (African Association for Lexicography) Afrička udruga za leksikografiju
- agregator (engl. aggregator, dictionary portal) v. rječnički portal
- AHlib digitalna zbirka slovenske
prijevodne književnosti od 1848. do 1918. godine
- AI (engl. artificial intelligence) > umjetna inteligencija
- Algemeen Nederlands Woordenboek (Rječnik suvremenoga nizozemskog jezika) korpusno utemeljen jednojezični rječnik nizozemskoga jezika [doznaj više...]
- algoritam za gramatičko tagiranje (engl. part-of-speech tagging algorithms) algoritam s pomoću kojega se provodi gramatičko tagiranje, odnosno s pomoću kojih se pridružuju oznake za vrstu riječi pojavnicama u korpusu
- anotacija (engl. annotation) dodavanje
jezičnih informacija elektroničkomu korpusu
- ANW (Algemeen Nederlands Woordenboek) opsežan znanstveni mrežni rječnik suvremenoga nizozemskog jezika sastavljen u Institutu za nizozemski jezik
- Asialex (The Asian Association for Lexicography) Azijska udruga za leksikografiju
- Australex (Australasian Association for Lexicography) Australazijska udruga za leksikografiju
- BabelNet višejezična leksička semantička i ontološka mreža koja se sastoji od 13 801 844 povezanih jezičnih čvorova koji se zovu Babelovi sinonimni skupovi (engl. Babel synsets). Za svaku je natuknicu osim definicije moguće dobiti i prijevod na druge jezike te sintetiziran izgovor istovrijednice, a za neke pojmove postoje i slikovni prikazi
- Baza frazema hrvatskoga jezika izdvojen korpus frazema unutar kolokacijske baze hrvatskoga jezika [doznaj više...]
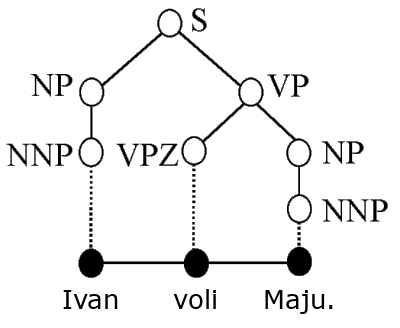
- banka stabala (engl. treebank) parsirani tekstni korpus
koji ima označenu sintaktičku i semantičku strukturu rečenica
- Beschrijving van de woordenschat (Opis vokabulara) projekt u okviru kojega se osmišljava jedinstveni leksički opis nizozemskoga jezika [doznaj više...]
- Bibliografija hrvatske frazeologije – Frazeo bibliografski rječnik (Ž. Fink-Arsovski – B. Kovačević – A. Hrnjak. Knjigra. 2017.) e-knjiga dostupna na mrežnim stranicama izdavača Knjige i mrežnim stranicama Hrvatskoga arhiva weba [doznaj više...]
- Canoonet gramatika, rječnik i jezični savjeti (Fragen Sie Dr. Bopp) za njemački jezik

- CJVT (Center za jezikovne vire in tehnologije) znanstvena ustanova Sveučilišta u Ljubljani koja se bavi istraživanjima povezanim s digitalnim jezičnim izvorima i jezičnim tehnologijama za suvremeni slovenski jezik
- CL (engl. computational linguistics) > računalno jezikoslovlje
- CLARIN (Common Language Resources and Technology Infrastructure) europska istraživačka infrastruktura za jezične izvore i tehnologiju koja digitalne jezične izvore čini dostupnima znanstvenicima, istraživačima i studentima svih disciplina, posebice u humanističkim i društvenim znanostima

- Clusty algoritam za provođenje leksičko-semantičke analiza za NLP: sense clustering dostupan na ELEXIS-ovim stranicama
- CMC (engl. computer-mediated communication) komunikacija koja se odvija uporabom jednoga ili više elektroničkih uređaja na mreži
- CroDeriV morfološki leksikon hrvatskih glagola koji obuhvaća oko 14 500 glagola rastavljenih na leksičke i tvorbene morfeme; glagoli istoga korijena međusobno su povezani te je uspostavljena opća morfološka struktura primjenjiva na sve hrvatske glagole (četiri mjesta za prefikse s desne i tri mjesta za sufikse s lijeve strane leksičkoga morfema)
- CroLTec (CROatian Learner TExt Corpus) korpus tekstova čiji su autori osobe koje uče hrvatski jezik kao ini jezik, obuhvaća tekstove od A1 do C1 razine učenja hrvatskoga jezika
- CroWN (Croatian Wordnet) > Hrvatski Wordnet
- ConceptNet višejezična baza koja omogućuje prikaz semantičkoga odnosa među riječima i izrazima
- Cosmas II sustav za pretragu i analizu korpusa i upravljanje njime (upotrijebljen npr. pri izradi elexika)

- crpenje naziva (engl. terminology extraction) postupak pronalaženja naziva određene struke u korpusu
- crpenje podataka (engl. data mining) razvrstavanje, organiziranje ili okupljanje velikoga broja podataka i izvlačenje relevantnih informacija, proces pronalaženja korisnih informacija u velikoj količini podataka
- čestoća (engl. frequency) broj pojavljivanja riječi ili izraza, primjerice u korpusu
- DARIAH-ERIC (Digital Research Infrastructure for the Arts and Humanities – European Research Infrastructure Consortium) digitalna istraživačka infrastruktura za umjetnost i humanističke znanosti, uključena u Europski konzorcij za istraživačku infrastrukturu (ERIC); zapravo je riječ o DARIAH-EU-u, koji je od 2014. godine pripao pod ERIC (European Research Infrastructure Consortium), pa se otad često (ali ne redovito) tako navodi
- DARIAH-EU (Digital Research Infrastructure for the Arts and Humanities – European Union) sveeuropska je digitalna istraživačka infrastruktura za umjetnost i humanističke znanosti, koja je od 2014. godine pripala pod ERIC, Europski konzorcij za istraživačku infrastrukturu (European Research Infrastructure Consortium), pa se otad često navodi kao DARIAH-ERIC (Digital Research Infrastructure for the Arts and Humanities – European Research Infrastructure Consortium)
- DARIAH-HR digitalna istraživačka infrastruktura za umjetnost i humanističke znanosti u Republici Hrvatskoj

- Das Digitale Wörterbuch der deutschen Sprache (DWDS) digitalni rječnički sustav u izradi koji se u trenutačno temelji na njemačkome rječniku Wörterbuch der deutschen Gegenwartssprache (WDG), čija se građa obogaćuje podatcima iz opsežnih tekstnih korpusa i drugih izvora prikupljenih u svrhu projekta; projekt se provodi u sklopu Centra za digitalnu leksikografiju njemačkoga jezika (ZDL)
- Das Lehnwortportal Deutsch des IDS portal posuđenica Leibnizova Instituta za njemački jezik (Leibniz-Institut für Deutsche Sprache) [doznaj više...]
- data mining > crpenje podataka
- deduplikacija (engl. deduplication) izbacivanje iz korpusa primjera koji se ponavljaju, npr. zbog navođenja antonim: reduplikacija
- deep (neural) learning > duboko (neuronsko) učenje
- dekodiranje (engl. decoding) proces obrnut od enkodiranja, u kojemu se znakove određenoga prilagođenog formata dobivene enkodiranjem vraća u njihov izvorni oblik
- DeReKo (Das Deutsche Referenzenkorpus) IDS-ov korpus govornoga jezika (sadržava oko 42 milijarde riječi po podatcima iz veljače 2018.), može se pretraživati s pomoću programa Cosmas II
- DeReWo IDS-ov korpus pisanoga jezika, može se pretraživati s pomoću programa Cosmas II
- Den Danske Ordbog jednojezični rječnik suvremenoga danskog jezika dostupan na portalu ordnet.dk Danskoga društva za jezik i književnost (Det Danske Sprog- og Litteraturselskab ) [doznaj više...]
- Det Norske Akademis ordbok rječnik Norveške akademije i najopsežniji rječnik norveškoga jezika, odnosno njegove inačice bokmål, od 2017. nalazi se na mreži [doznaj više...]
- DGD IDS-ova baza govornoga korpusa njemačkoga jezika, koju sačinjavaju 92 korpusa i koja sadržava oko 4000 sati audiozapisa i videozapisa; bazom se mogu koristiti registrirani korisnici
- DH (engl. digital humanities) > digitalna humanistika
- dictionary matrix > rječnička matrica
- digitalizacija (engl. digitization) pretvorba teksta, slike, zvuka, pokretnih slika (filmova i videa) ili trodimenzijskoga oblika nekoga objekta u digitalni oblik, računalnu datoteku koja se može obrađivati, pohranjivati ili prenositi računalima i računalnim sustavima
- digitalna humanistika (engl. digital humanities, DH) znanstveno područje koje se bavi primjenom računalnih ili digitalnih tehnologija u humanističkim znanostima
- DSNA (Dictionary Society of North America) Sjevernoameričko leksikografsko društvo
- DFKI (Deutsches Forschungszentrum für Künstliche Intelligenz) Njemački istraživački centar za umjetnu inteligenciju
- duboko (neuronsko) učenje (engl. deep neural network, deep (neural) learning) strojno učenje koje se odnosi na računala koja uče na temelju neuronskih mreža s pomoću kojih mogu, na temelju prethodnih zadataka, naučiti samostalno donositi odluke povezane s obradom podataka
- DWDS (Das Digitale Wörterbuch der deutschen Sprache)
- ekstrakcija podataka (engl. extraction of data) postupak analize i prikupljanja određenih podataka iz jednoga ili više različitih podatkovnih izvora (najčešće baza podataka) kako bi se došlo do relevantnih informacija
- elektronički rječnik (engl. electronic dictionary, e-dictionary) rječnik u digitalnome obliku
- e-leksikograf (engl. e-lexicographer) stručnjak koji se bavi teorijom i praksom izrade elektroničkih leksikografskih djela
- e-leksikografija (engl. e-lexicography) znanstvena disciplina koja se bavi teorijom i praksom izrade elektroničkih leksikografskih djela
- e-leksikografkinja (engl. e-lexicographer) stručnjakinja koji se bavi teorijom i praksom izrade elektroničkih leksikografskih djela
- eLex konferencija o e-leksikografiji koja se održava svake druge godine
- Elexifier sustav za rječničku konverziju utemeljen na oblačnome računalstvu koji s pomoću naprednoga XML parsiranja i strojnoga učenja pomaže u pretvaranju rječnika u formatu .pdf ili .xml u standardizirani računalno čitljiv oblik
- Elexifinder alat za pretraživanje koji pomaže leksikografima i drugim istraživačima da pronađu znanstvene rezultate u leksikografiji i srodnim poljima, dostupan na ELEXIS-ovim stranicama
- elexiko mrežni je rječnik suvremenoga njemačkog jezika Leibnizova Instituta za njemački jezik (Leibniz-Institut für Deutsche Sprache) [doznaj više...]
- ELEXIS (European Lexicographic Infrastructure, Europska leksikografska struktura) platforma je i projekt čiji je nastanak potaknut činjenicom da u Europi postoji velik broj u leksikografskome radu nedovoljno povezanih i koordiniranih ustanova u kojima se stvaraju rječnici ili prikupljaju leksikografski podatci eNeL (European Network of e-Lexicography) > Europska mreža za e-leksikografiju [doznaj više...]
- enkodiranje (engl. encoding) proces prebacivanja skupa znakova (koji mogu uključivati slova, brojke, pravopisne znakove, simbole itd.) u određeni format koji te znakove može uspješno pohraniti i prenijeti za ispravan prikaz na zaslonu
- e-rječnik v. elektronički rječnik
- error tagging > označivanje pogrešaka
- eSSKJ > Slovar slovenskega knjižnega jezika
- EURALEX (European Association for Lexicography, Europska udruga za leksikografiju), udruga je koja okuplja stručnjake iz cijeloga svijeta koji se bave leksikografijom i s njom povezanim područjima; konferencije se održavaju svake druge godine. Dio je mreže GLOBALEX-a, udruge stručnjaka koji se bave izradom rječnika i drugih jezičnih izvora. Inicijativa je pokrenuta 2015. godine na konferenciji eLex u Ujedinjenome Kraljevstvu te uključuje predstavnike udruga za leksikografiju utemeljenih na različitim kontinentima: afričku (AFRILEX), azijsku ( ASIALEX), australazijsku (AUSTRALEX), europsku (EURALEX) i sjevernoameričku (DSNA); cilj je GLOBALEXA olakšati razmjenu znanja i suradnju u području jezikoslovlja i jezične tehnologije, promicati stvaranje, istraživanje, razmjenu i integraciju leksikografskih izvora i rješenja. (Lana Hudeček)

- Europska mreža za e-leksikografiju (engl. European Network of e-Lexicography, eNeL), COST-ova je akcija koja je završila 2017. godine, a čiji je cilj bio utemeljiti europsku mrežu leksikografa kako bi se strukturirano pristupilo omogućavanju lakšega pristupa rječnicima, razmjeni leksikografskih znanja, zajedničkih standarda i rješenja te razvoju zajedničkoga pristupa e-leksikografiji – pokretač je Europske mreže za e-leksikografiju ELEXIS

ciljevi COST-ove akcije European Network of e-Lexicography
- Europski rječnički portal portal koji po unaprijed određenim kriterijima okuplja kvalitetne mrežne rječnike europskih jezika te pomaže korisnicima stranice da ih lakše pronađu; portal održavaju stručnjaci Europske mreže za e-leksikografiju
- FIDA korpus slovenskoga jezika sastavljen od tekstova iz različitih izvora nastalih između 1990. i 2000. godine koji sadržava 100 milijuna pojavnica
- FidaPLUS nadogradnja korpusa slovenskoga jezika FIDA; dodatno su prikupljeni tekstovi nastali do 2006. koji uključuju društvene mreže, novine, blogove i književna djela; sadržava oko 600 milijuna pojavnica; naslijedio ga je korpus Gigafida
- FrameNet leksička baza podataka engleskoga jezika sa slobodnim pristupom utemeljena na primjerima uporabe riječi u stvarnim tekstovima; građa je organizirana u više od 1200 semantičkih okvira
- Fran portal Inštituta za slovenski jezik Frana Ramovša ZRC SAZU koji objedinjuje rječnike, izvore slovenskoga jezika i portale koji su stvoreni ili se stvaraju u Institutu za slovenski jezik Frana Ramovša ZRC SAZU i rječnike koji su digitalizirani u Institutu [doznaj više...]
- Franček portal Inštituta za slovenski jezik Frana Ramovša
ZRC SAZU namijenjen učenicima, njihovim učiteljima i roditeljima, kojemu je
cilj prilagođenim jezičnim podatcima uvesti djecu i mlade od 1. razreda osnovne
škole nadalje u uporabu rječnika i gramatike
- Frazemi – baza frazemskih etimologija baza je nastala usporedno s radom na Hrvatskome mrežnom rječniku – Mrežniku te su podatci iz te baze uključeni u Mrežnik [doznaj više...]
- frekvencija (engl. frequency) v. čestoća
- frekventnost (engl. frequency) v. čestoća
- FRENK projekt koji povezuje suvremene kvantitativne i kvalitativne višedisciplinske pristupe (metode korpusnoga jezikoslovlja, kritičku analizu diskursa, pravnu analizu i metode sociološkoga istraživanja) kako bi se istražila uporaba i percepcija društveno neprihvatljivoga oblika komunikacije u društvenome i kulturnome kontekstu
- GALA (Globalization and Localization Association) svjetska neprofitna udruga za jezičnu industriju
- GDEX (Good Dictionary Examples) alat ugrađen u SketchEngine koji omogućuje pronalaženje dobrih primjera u korpusu; dobrim se primjerom smatra primjer koji je tipičan, ilustrativan, primjerene duljine i puna rečenica; ovisno o načelima obrade leksikografi prilagođuju primjere pronađene u korpusu, ali mogućnost automatskoga odabira dobrih primjera olakšava rječničku obradu
- Gigafida korpus slovenskih tekstova koji pripadaju različitim funkcionalnim stilovima i žanrovima; uključuje tekstove iz novina i časopisa, knjiga i udžbenika, s mrežnih stranica, transkripte parlamentarnih rasprava itd.; sadržava oko 1,2 milijarde pojavnica
- Gigafida 2.0 nadograđena inačica korpusa Gigafida; dodani su tekstovi poput školske literature i odabranih književnih djela; sadržava oko 1,5 milijardi riječi te je korpus također razvijen na tehničkoj razini, što omogućuje uklanjanje duplikata tekstova, poboljšava točnost jezičnoga označavanja i odvajanje tekstova na standardnome jeziku od ostalih tekstova
- Globalex udruga stručnjaka koji se bave izradom rječnika i drugih jezičnih izvora; inicijativa je pokrenuta 2015. godine na konferenciji eLex u Ujedinjenome Kraljevstvu te uključuje predstavnike svih udruga za leksikografiju utemeljenih na različitim kontinentima: afričku (Afrilex), azijsku (Asialex), australazijsku (Australex), europsku (Euralex) i sjevernoameričku (DSNA); cilj je Globalexa olakšati razmjenu znanja i suradnju između svojih članova i drugih koje zanimaju jezikoslovlje i jezične tehnologije, promicati stvaranje, istraživanje, razmjenu, diseminaciju, integraciju i uporabu leksikografskih izvora i rješenja
- GOS (Korpus Govorjene Slovenščine) korpus govornoga slovenskog jezika, koji sadržava transkripcije govora u različitim situacijama (radijskih i televizijskih emisija, predavanja, razgovora u krugu prijatelja i obitelji, sastanaka itd.); korpus je nastao u okviru projekta Sporazumevanje v slovenskem jeziku
- govoreći rječnik (engl. talking dictionary ) interaktivni mrežni rječnik koji korisniku omogućuje da čuje visokokvalitetne audiozapise te snima i prenosi novi sadržaj i slike
- gramatičko tagiranje (engl. part-of-speech tagging) pridruživanje oznake za vrstu riječi pojavnicama u korpusu
- gramatika skica (engl. Sketch Grammar) jezični opis na kojemu se temelje skice riječi za određeni jezik; nastaje pretpostavljanjem podataka potrebnih za jezični opis ili leksikografsku obradu i testiranjem rezultata; niz pravila kojima se traže kolokacije u tekstnome korpusu te se kategoriziraju prema gramatičkim odnosima, npr. objektima, subjektima, modifikatorima itd.; piše se u jeziku CQL, a rezultat se prikazuje u obliku skica riječi u sučelju SketchEngine
- Grammis baza gramatičkih podataka Leibnizova Instituta za njemački jezik (Leibniz-Institut für Deutsche Sprache) [doznaj više...]
- govoreni korpus > govorni korpus
- govorni korpus korpus koji sačinjavaju zvučni zapisi te prijepisi spontanoga govora
- Hašek (fonetizirano prema Hascheck – Hrvatski akademski spelling checker) pravopisni provjernik za hrvatski jezik razvijen na Fakultetu elektrotehnike i računarstva Sveučilišta u Zagrebu, 2016. zamijenjen novijom inačicom
- hibridizacija spajanje različitih referentnih djela (npr. različitih baza) u jedinstven proizvod, e-rječnik
- hipertekst (engl. hypertext) tekstna struktura koja se sastoji od međusobno povezanih jedinica informacije (engl. node) prikazana na elektroničkome uređaju; hipertekst nema jedinstven redoslijed čitanja, nego ga čitatelj dinamički određuje, tj. određuje ga tijekom čitanja
- Historische Woordenboeken (Povijesni rječnici) portal na kojemu su javno dostupni i pretraživi povijesni rječnici nizozemskoga i frizijskoga jezika [doznaj više...]
- HLT (engl. human language technology) > jezične tehnologije
- HOBS (Hrvatska ovisnosna banka stabala, engl. Croatian Dependency Treebank)
- hrLex hrvatski morfološki leksikon
- HNK (Hrvatski nacionalni korpus) v. Hrvatski nacionalni korpus
- HR4EU mrežni portal namijenjen strancima koji uče hrvatski jezik izrađen u Zavodu za lingvistiku na projektu koji financira Europska unija u okviru Europskoga socijalnog fonda.
- Hrvatska ovisnosna banka stabala (HOBS, engl. Croatian Dependency Treebank) dva korpusa Hrvatskoga nacionalnoga korpusa (prvi je dio novinskoga potkorpusa – tjednik Croatia Weekly, drugi uključuje 500 rečenica iz tečajeva za hrvatski jezik dostupnih na portalu HR4EU)označena na morfosintaktičkoj i ovisnosnoj razini te na razini semantičkih uloga
- Hrvatska jezična riznica korpus Instituta za hrvatski jezik
- Hrvatski lematizacijski poslužitelj mrežni program za pretraživanje Hrvatskoga morfološkoga leksikona i njegovu uporabu u računalnojezikoslovnim postupcima: pri generiranju i prepoznavanju oblika hrvatskih riječi, tj. svođenju na osnovni oblik (lematiziranju)
- Hrvatski morfološki leksikon baza koja se sastoji od više od 45 000 riječi općega jezika, 15 000 osobnih muških i ženskih imena i 50 000 prezimena registriranih u Republici Hrvatskoj te 3 900 000 njihovih oblika; morfosintaktički opisi usklađeni su s MulTextEast v 3.0 preporukama za hrvatski jezik
- Hrvatski jezični portal javno dostupna rječnička baza hrvatskoga jezika, zajednički projekt nakladničke kuće Znanje i Srca; uključuje 116 516 natuknica
- Hrvatski mrežni korpus v. hrWaC
- Hrvatski nacionalni korpus (HNK) jedan od triju korpusa hrvatskoga jezika (uz hrWaC i Hrvatsku jezičnu riznicu); obaseže više od 105 milijuna pojavnica i sastoji se od niza potkorpusa koji se mogu pretraživati pojedinačno i zajedno; za pretraživanje HNK-a potreban je slobodno dostupan program Bonito
- Hrvatski Wordnet (CroWN) semantička mreža hrvatskoga jezika koja slijedi strukturu prinstonskoga WordNeta i povezana je s njegovom inačicom 3.0; temelj organizacije CroWN-a sinonimni su skupovi
- hrWaC (Hrvatski mrežni korpus) lematiziran i na morfosintaktičkoj razini označen korpus hrvatskoga jezika; inačica 2.1. sadržava 1,4 milijarde pojavnica
- html (HTML, Hypertext Markup Language) standardizirani jezik za označavanje podataka, koji se primjenjuje za stvaranje mrežnih stranica i mrežnih aplikacija
- Íslex mrežni višejezični islandsko-nordijski rječnik namijenjen neizvornim govornicima, koji se sastoji od islandske baze te prijevoda na šest nordijskih jezika: danski, švedski, dva norveška standarda ( bokmål i nynorsk), ferski i finski [doznaj više...]
- Ispravi.me pravopisni provjernik za hrvatski jezik razvijen na Fakultetu elektrotehnike i računarstva Sveučilišta u Zagrebu koji je 2016. zamijenio svoju stariju inačicu Hašek
- izbornik (engl. menu) prikaz na početku dugih rječničkih članaka koji sažeto prikazuje značenja natuknice
- jezične tehnologije (engl. language technology) tehnologije koje uključuju obradu prirodnoga jezika (NLP) i računalno jezikoslovlje te govorne tehnologije; sinonim: LT, HLT
- jezični alati (engl. linguistic tools) programi koji se razvijaju na temelju jezičnih izvora kao ishodišnih podataka te obrađuju postojeće jezične izvore ili služe za stvaranje novih jezičnih izvora; omogućuju jednostavniju, bržu i jeftiniju uporabu prirodnoga jezika u računalnome okružju
- jezični izvori (engl. language resources) digitalno su usustavljena i pretraživa jezična građa koja dolazi u dva oblika: a) kao korpusi, tj. zbirke tekstova na jednome ili više jezika koje služe kao znatna količina jezičnih podataka za temeljna istraživanja o jeziku/jezicima i njihovim međuodnosima te b) kao digitalni rječnici, lako dostupni i pretraživi mrežno ili izvanmrežno; na temelju jezičnih izvora kao ishodišnih podataka razvijaju se jezični alati koji ili obrađuju postojeće jezične izvore ili služe za stvaranje novih jezičnih izvora
- jezični resursi > jezični izvori
- JT v. jezične tehnologije
- JSON (Java Script Object Notation) datoteka koja omogućuje organiziranu pohranu informacija u zagradama, a informacije se mogu poslije lako i brzo učitati na mrežnim stranicama; u nekim se slučajevima može upotrijebiti kao zamjena za XML datoteke
- kanonski oblik (engl. canonical form) osnovni oblik riječi u kojemu se u pravilu uspostavlja rječnička natuknica; za imenice to je nominativ jednine, za glagole infinitiv, za pridjeve nominativ jednine muškoga roda itd.; ako se riječ nikad ne pojavljuje u kanonskome obliku, zapisuje se u najtipičnijemu, kanonskomu obliku najbližemu obliku, npr. se
- Klexicon (Kinder lexicon) Wikipedia za djecu
- konkordancija (engl. concordance) popis riječi sa svim oblicima u kojima se pojavljuju zajedno s kontekstom i oznakom izvora, koji se nalaze u nekome korpusu
- kolokacija (engl. collocation) skup od najmanje dvije punoznačne riječi koje se često pojavljuju zajedno
- konkordanca (engl. concordance) > konkordancija
- konkordancer (engl. concordancer) računalni program koji automatski konkordira tekst
- konkordansa (engl. concordance) > konkordancija
- KonText javno dostupan alat za pretraživanje korpusa, moguće je besplatno korištenje njime za pretraživanje korpusa na Clarinovim stranicama
- konverzijski alati (engl. conversion tools) alati koji omogućuju uporabu rječničkoga sadržaja u stvaranju novih rječničkih ili jezičnih sadržaja
- Kookurenz analyse alat za pretragu teksta (upotrijebljen pri izradi elexika)
- KorAP je skalabilan, fleksibilan i održiv sustav otvorenoga koda Leibnizova Instituta za njemački jezik (Leibniz-Institut für Deutsche Sprache) za rad s korpusima [doznaj više...]
- korpus (engl. corpus) zbirka tekstova prirodnoga jezika sastavljena po određenome kriteriju, skup jezičnih odsječaka (tekstova) koji su odabrani i skupljeni prema jasnim jezikoslovnim kriterijima radi dobivanja određenoga jezičnog uzorka
- korpus standardnoga jezika korpus tekstova pisanih standardnim jezikom
- korpusno utemeljen rječnik (engl. corpus based dictionary) rječnik u kojemu se obrađivač služi korpusom, ali može slobodno procijeniti što treba unijeti u rječnik te rječnik može po potrebi dopunjavati i riječima iz drugih izvora te kolokacijama i značenjima koji nisu potvrđeni u korpusu
- korpusom vođen rječnik (engl. corpus driven dictionary) rječnik u kojemu se obrađivač služi isključivo korpusom pa se u rječniku nalazi samo ono što se nalazi u korpusu
- korpusna lingvistika v. korpusno jezikoslovlje
- korpusno jezikoslovlje (engl. corpus linguistics) grana jezikoslovlja koja se bavi jezičnom analizom strojno izrađenih korpusa pisanoga ili govornoga jezika
- kratka definicija (engl. menu definition) definicija koja se pokazuje u izborniku, prikazu na početku dugih rječničkih članaka koji sažeto prikazuje značenja natuknice
- Kres korpus slovenskoga jezika nastao unutar projekta Komunikacija na slovenskome jeziku u razdoblju od 2008. do 2012. godine; sadržava gotovo 100 milijuna pojavnica
- lema (engl. lemma) kanonski oblik riječi (u morfologiji i leksikografiji), kanonski oblik pojavnice (u korpusnome jezikoslovlju), tagirana vrijednost
- lematiziranje (engl. lemmatization, lemmatisation) uspostava kanonskoga oblika pojavnice
- lematizirati (engl. to lemmatize) uspostavljati kanonski oblik pojavnice
- Lexical Computing tvrtka je koja djeluje u području korpusne i računalne lingvistike te promiče pristup u kojemu u jezičnim istraživanjima korpusi imaju središnju ulogu [doznaj više...]
- Lexicographic news feed ELEXIS-ov servis koji izlučuje najnovije novinske članke na (trenutačno) više od 35 jezika povezane s leksikografijom iz velikoga broja (30 000) novinskih izvora, dostupan na ELEXIS-ovim stranicama
- Lexin švedski mrežni rječnik namijenjen neizvornim govornicima [doznaj više...]
- Lexonomy sustav za sastavljanje i mrežno objavljivanje rječnika utemeljen na oblačnome računalstvu; može se prilagoditi velikim (općim rječnicima) i manjim leksikografskim projektima (specijaliziranim ili terminološkim rječnicima i glosarima) povezan sa SketchEngineom tako da SketchEngine može poslati leksikografske podatke u Lexonomy kako bi se dobili automatski generirani rječnički nacrti te tako da Lexonomy može izvlačiti podatke iz SketchEngineovih korpusa tijekom procesa sastavljanja rječničkih članaka
- Linguistic Linked Open Data (LLOD) pokret vezan za izdavanje jezičnih izvora i programa za jezikoslovce i obrađivače prirodnoga jezika koji moraju bit izdani pod licencijom zajedničkoga kreativnog dobra (engl. Creative Commons ili CC), biti dostupni preko jedinstvene mrežne adrese, koristiti se suvremenim mrežnim standardima za podjelu resursa (HTML, RDF, JSON) te nuditi poveznice na druge korisne sadržaje
- link > poveznica
- linked data v. povezani podatci
- LLOD > Linguistic Linked Open Data
- LOD (engl. linked open data) 1. tip povezanih podataka (Linked Data) koji se objavljuje pod otvorenom licencijom, 2. metoda objavljivanja strukturiranih podataka koja omogućuje uzajamno povezivanje
- LT (engl. language technology) > jezične tehnologije
- LT Advisor GALA-ina platforma za opis jezičnih tehnologija, ocjene i oglede
- matrični rječnik (engl. matrix dictionary) univerzalna leksikografska metastrukture, rječnik koji obuhvaća više jezika, leksikografski izvor predviđen planom projekta Elexis; univerzalni registar/mreža semantičkih odnosa koji služe kao semantički posrednički jezik za opću razmjenu znanja, usmjeren na težak višeznačenjski vokabular (jednorječni i višerječni), moderan i povijesni
- matrix dictionary > matrični rječnik
- meni (engl. menu) v. izbornik
- menu definition > kratka definicija
- menu v. izbornik
- Metanet javno mrežno dostupna baza konceptualnih i jezičnih metafora, metonimija te predodžbenih shema, kognitivnih primitiva i semantičkih okvira hrvatskoga jezika s pripadajućim leksičkim jedinicama
- mrežni repozitorij (engl. web repository) računalni sustav za pohranu, preuzimanje, čuvanje, odabir i izlučivanje podataka na mreži
- mrežni rječnik (engl. web-born dictionary) rječnik izvorno osmišljen za mrežnu platformu, što uključuje lakše međusobno povezivanje unutarrječničkoga sadržaja (cross-referencing) i rječničkoga sadržaja s drugim mrežnim sadržajima, unošenje u rječnik sadržaja poput audiozapisa i videozapisa te mogućnost komunikacije s korisnicima koji mogu biti i aktivni sudionici u stvaranju rječničkoga sadržaja
- MSD (engl. morfo-syntactic description) > morfosintaktički opis
- multimodalnost mogućnost uporabe različitih načina prikaza informacija (npr. tekstnoga, zvučnoga, slikovnoga) u e-rječnicima
- natuknica (engl. headword) riječ iz rječničkoga abecedarija koja se nalazi na početku rječničkoga članka i za kojom slijedi njezina obrada
- NAISC 1.0 alat za povezivanje skupova podataka dostupan na ELEXIS-ovim stranicama
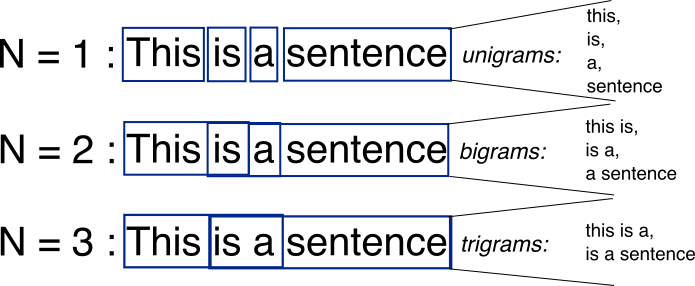
- n-gram sekvencija određene duljine koju sačinjavaju znakovi ili riječi koje se pojavljuju unutar teksta; pri radu s korpusima n-grami se odnose na sekvencije riječi; unigram je jedna riječ, bigram je sekvencija od dvije riječi, trigram je sekvencija od tri riječi itd.
- n-gram overlap > preklapanje n-grama
- nacionalni korpus (engl. national corpus) 1. opći korpus koji uključuje velik broj tekstova reprezentativnih za određeni jezik, 2. v. opći korpus
- NER (Named-entity recognition) računalni proces u kojem se pronalaze, pohranjuju i sortiraju dijelovi teksta u određene zadane kategorije (npr. u neobrađenomu tekstu pronalaze se sva imena te automatski izdvajaju u kategorije imena ljudi, imena mjesta, imena tvrtki itd.)
- Nieuwe woorden (Novotvorenice) mrežni popis novotvorenica u nizozemskome jeziku [doznaj više...]
- NLP (engl. natural language processing) > obrada prirodnih jezika
- NoSketchEngine javno dostupan alat za pretraživanje korpusa s pomoću kojega se može pretraživati korpus hrWaC
- Nova beseda govorni korpus slovenskoga jezika koji se izrađuje na Inštitutu za slovenski jezik Frana Ramovša u Ljubljani
- obrada prirodnih jezika (engl. natural language processing) 1. jezikoslovno područje usmjereno na interakciju između prirodnoga jezika i računalâ; analiza i razumijevanje složenih jezičnih izraza prirodnoga jezika s pomoću računala; primjenom obrade prirodnih jezika moguće je ostvariti različite zadaće (npr. automatsko sažimanje, prevođenje, prepoznavanje glasa, segmentacija tema itd.), 2. računalno jezikoslovlje
- odostražni rječnik (engl. reverse dictionary) rječnik u kojemu su riječi abecedirane od kraja; odostražni rječnik Rückläufiges Wörterbuch des Serbokroatischen (1965. – 1967.) mrežno je dostupan na https://www.uibk.ac.at/slawistik/institut/matesic.html. Demoinačica odostražnoga rječnika naziva za vršitelje/vršiteljice radnje (https://borna12.gitlab.io/odostraznji-mz/, izradio Josip Mihaljević):
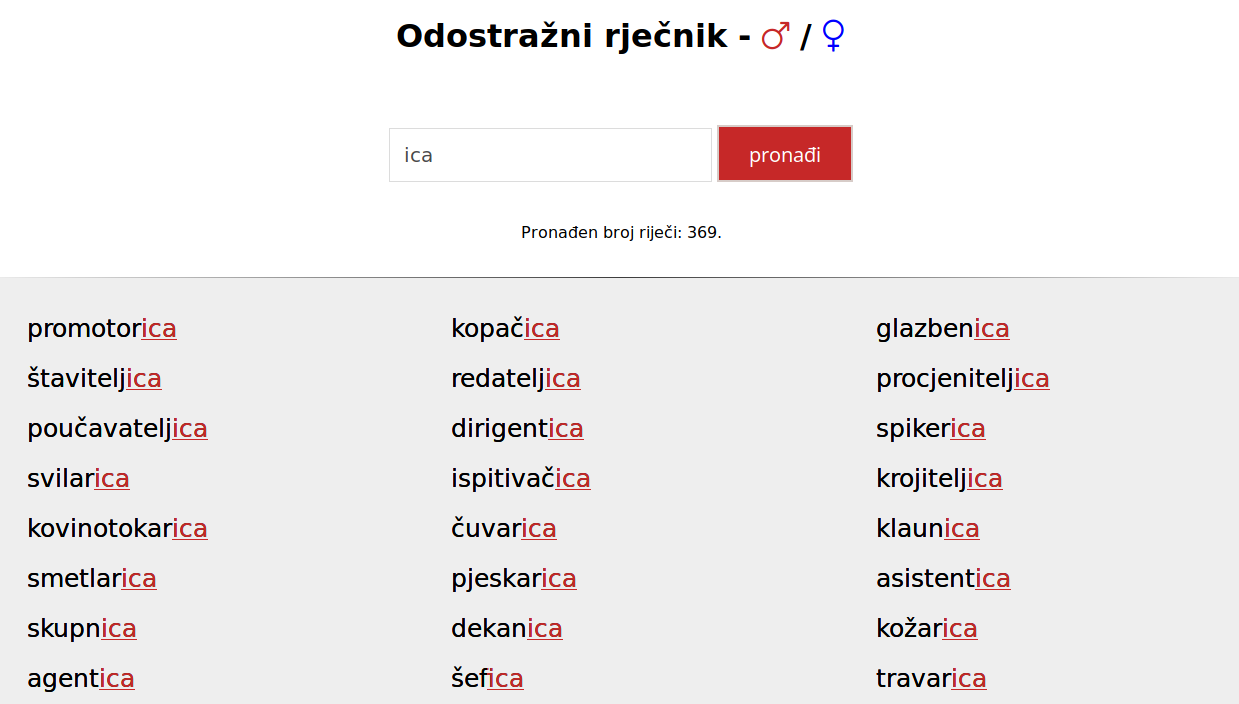
- odostražnik v. odostražni rječnik
- OmegaWiki projekt masovne podrške (engl. crowdsourcing) u stvaranju rječnika svih jezika, koji uključuje leksičke, terminološke i ontološke podatke spojene putem relacijske baze podataka
- OneClickDictionary (OCD) modul za sastavljanje skice riječi koji povezuje sustav za upravljanje korpusom (SketchEngine ili noSketch Engine) s Lexonomyjem i omogućuje automatsko stvaranje rječničkoga nacrta koji sadržava natuknice, oblike riječi, primjere i kolokacije itd., a koji u Lexonomyju dalje uređuje leksikograf koji se u potpunosti može usredotočiti na tu, središnju fazu leksikografskoga rada
- opći korpus (engl. general corpus) korpus koji je reprezentativan za jezik u cjelini, koji se sastoji od tekstova koji pripadaju različitim tekstnim vrstama, područjima i stilovima
- OWID portal Leibnizova Instituta za njemački jezik (Leibniz-Institut für Deutsche Sprache) koji prikuplja više rječnika i internetskih bibliografija (uglavnom za istraživačke svrhe) na jednome mjestu (digitalne i e-rječnike), koje je moguće istodobno pretraživati [doznaj više..]
- Oxygen program za rječničku obradu (upotrijebljen npr. pri izradi elexika)
- označavanje korpusa v. tagiranje
- označivanje pogrešaka (engl. error tagging) označivanje jezičnih pogrešaka u tekstu korpusa koje računalo može razumjeti
- označivanje semantičkih uloga (engl. semantic role labeling) proces u prirodnoj obradi jezika u kojemu se označava semantička uloga riječi ili izraza u rečenici (npr. agent, cilj i rezultat)
- pametna leksikografija (engl. smart lexicography ) leksikografija usmjerena prikazu rječnika na različitim uređajima, prilagodba leksikografskih djela novim digitalnim formatima, npr. pametnim telefonima
- paralelni korpus > usporedni korpus
- Parlametar alat koji s pomoću analize glasa i transkripata zastupničkih nastupa olakšava praćenje rada Hrvatskoga sabora
- parsiranje (engl. parsing) raščlanjivanje rečenice u računalnoj obradbi jezika
- parsirati (engl. to parse) raščlaniti rečenicu u računalnoj obradbi jezika
- parser (engl. parser) računalni program za analizu rečenice do osnovnih sintaktičkih kategorija ili do riječi
- parsemsko stablo (engl. parse tree) prikaz raščlanjene rečenice u obliku stabla u računalnoj obradbi jezika
- PARSEME (PARSing and Multi-word Expressions) interdisciplinarna znanstvena mreža usmjerena na ulogu višerječnih jedinica (MWE – multiword expression) u parsiranju, cilj joj je poboljšati računalnu učinkovitost obrade prirodnoga jezika
- PDF (Portable Document Format) format u kojemu dokument čuva sve značajke otisnutoga dokumenta u obliku e-slike
- podatkovno rudarenje (engl. data mining) > crpenje podataka
- pojavnica (engl. token) sve što se nalazi između dva znaka koja služe kao graničnici (svako individualno pojavljivanje); svaka pojava jezične jedinice u korpusu, na razini riječi svaki oblik uključen u leksem
- ponovna uporaba rječničkoga sadržaja (engl. reuse of dictionary content) povezivanje rječničkoga sadržaja s drugim rječnicima i jezičnim izvorima kako bi se stvorili novi rječnički (jezični) sadržaji, integracija, povezivanje i spajanje rječničkih sadržaja kojoj je važan preduvjet kompatibilnost formata
- POS tagging (part-of-speech tagging) > gramatičko tagiranje
- POS tagging algoritmi > algoritmi za gramatičko tagiranje
- POST (part-of-speech tagging) > gramatičko tagiranje
- potkorpus (engl. subcorpus) izdvojeni dio korpusa koji može bit određen na temelju tematskih sadržaja, medija (govorni ili pisani potkorpus), vremenu nastanka teksta, izvora itd.; upotrebljava se za lakšu organizaciju sadržaja u korpusu
- povezani podatci (engl. linked data) strukturirani podatci uzajamno povezani s drugim podatcima na semantičkoj mreži (engl. Semantic Web) kako bi ih se lakše moglo pronaći s pomoću semantičkih upita (engl. semantic queries)
- poveznica (engl. link) veza između dviju mrežnih stranica; veza između hipertekstnoga sadržaja i kojega drugog hipertekstnog ili bilo kakva multimedijskoga sadržaja (mrežne stranice, glazbe, slike, filma, animacije)
- Praška ovisnosna banka stabala baza podataka koja sadržava veliku količinu teksta na češkome jeziku, kojemu su pridružene složene i međusobno povezane morfološke, sintaktičke i semantičke oznake
- preklapanje n-grama (engl. n-gram overlap) metoda kojom se provjerava preklapanje istih n-grama u različitim dokumentima
- pretraživač (engl. search engine) računalni program s pomoću kojega se pretražuju informacije na internetu
- prilagodljivost (engl. customisation) značajka e-rječnika koji se na neki način prilagođava korisniku
- prostor za pohranu (engl. storage space) prostor u e-rječniku koji je slobodan za pohranu podataka, takoreći neograničen
- prostor za prezentaciju (engl. presentation space) prostor koji je dostupan za prezentaciju podataka u e-rječniku, prostor koji je korisnicima vidljiv na njihovim uređajima, manji od prostora za pohranu
- računalna lingvistika > računalno jezikoslovlje
- računalno jezikoslovlje (engl. computational linguistics) interdisciplinarno područje povezano s računalnim modeliranjem prirodnoga jezika, temeljenim na statistici ili pravilima, kao i s proučavanjem odgovarajućih računalnih pristupa jezičnim pitanjima
- rastući rječnik (engl. growing dictionary) rječnik čiji se sadržaj periodično revidira i dopunjuje novim podatcima
- različnica (engl. type) pojedinačna riječ koja se razlikuje od druge riječi (npr. u korpusu riječ koja se bilježi samo pri prvome pojavljivanju jer se sa svakim sljedećim pojavljivanjem smatra pojavnicom), jedinstveni oblik pojavnice iz korpusa
- reduplikacija (engl. reduplication) ponavljanje primjera u korpusu, npr. zbog navođenja antonim: deduplikacija
- REFER prvi sustav koji je nastao u Institutu za njemački jezik (Institut f ür Deutsche Sprache) za rad s upitnim jezicima koji se upotrebljavaju za dohvaćanje podataka iz korpusa
- regex v. regularni izraz
- regularni izraz (engl. regular expression) zadani niz znakova čija se kombinacija može upotrijebiti za pronalaženje određenih dijelova teksta, izraz koji se uspostavlja za pretraživanje korpusa s pomoću alata SketchEngine i NoSketchEngine za traženje ciljanih gramatičkih ili leksičkih uzoraka (popis regularnih izraza dostupan je na https://sketchengine.co.uk/documentation/corpus-querying/). Regularni izrazi iz SketchEngineova kalendara za 2018.:

- rječnička matrica (engl. dictionary matrix) jedinstvena sveobuhvatna rječnička struktura nastala opsežnim povezivanjem ključnih strukturnih elemenata u različitim vrstama rječnika, usmjerena na (izravno ili neizravno) povezivanje postojećih leksikografskih izvora na razini natuknice, ali i na razni ostalih strukturnih elemenata, pa tako i na značenjskoj razini putem BabelNeta (jedan od koraka u projektu Elexis koji dalje vodi stvaranju matričnoga rječnika)
- rječnički članak (engl. entry) članak u kojemu se nalazi obrada pojedine natuknice
- rječnički portal (engl. dictionary portal, aggregator) (rječničke) mrežne stranice koje omogućuju pristup drugim rječničkim mrežnim stranicama
- rječnik otvorenoga pristupa (engl. open source dictionary ) rječnik dostupan za opću uporabu, rječnik utemeljen na kodu kojim se svi mogu služiti sinonim: rječnik slobodnoga pristupa, slobodno/besplatno dostupan rječnik
- rječnik prilagodljiv korisnicima (engl. adaptable dictionary) rječnik koji korisnici sami mogu prilagoditi svojim potrebama
- rječnik koji se prilagođava korisnicima (engl. adaptive dictionary) rječnik koji se sam prilagođava korisnicima na temelju podataka koje su unijeli ili pretraživali
- ReLDI (Regional Linguistic Data Initiative) mreža istraživača koji se bave jezikom, rezultat dvogodišnjega institucijskoga partnerstva znanstvenih organizacija u Švicarskoj, Srbiji i Hrvatskoj u okviru programa SCOPES Švicarske nacionalne fondacije za znanost
- reprezentativni korpus (engl. representative corpus) korpus koji veličinom i kvalitetom obuhvaća mnogo mogućnosti za obradu riječi i rečenica koje su potrebne korisniku; reprezentativnost se uglavnom određuje s obzirom na veličinu i sadržaj korpusa te kako se tekstovi iz tih sadržaja dohvaćaju za izradu jezičnih uzoraka (engl. sampling)
- responzivni rječnik (engl. responsive dictionary) rječnik koji se može pregledavati na različitim računalnim uređajima te na različitim mrežnim preglednicima
- retrodigitalizacija (engl. retrodigitization) prenošenje nedigitalnih podataka (npr. iz tiskanih knjiga, snimaka, filmova) u digitalni oblik
- rudarenje podataka (engl. data mining) > crpenje podataka
- semantic role labeling (SRL) > označivanje semantičkih uloga
- semantička mreža (engl. semantic web) skup značenja i pojmova koji su u nekoj mjeri povezani sa središnjim značenjem
- sinonimni skup (engl. synset) skup sinonima međusobno zamjenjivih u najmanje jednome kontekstu
- sinskup (engl. synset) > sinonimni skup
- Slovar slovenskega knjižnega jezika (eSSKJ) jednojezični mrežni rječnik slovenskoga jezika dostupan na portalu Fran Inštituta za slovenski jezik Frana Ramovša ZRC SAZU [doznaj više...]
- sloWaC (Slovenski mrežni korpus) lematiziran i morfološki označen korpus slovenskoga jezika; inačica 2.0. sadržava 1,2 milijarde pojavnica
- SketchEngine alat za pretragu i izgradnju korpusa tvrtke Lexical Computing, koji sadržava mnoštvo alata koji omogućuju analizu velikih korpusa te potpuno automatiziranu izgradnju rječnika
- SketchGrammar > gramatika skica
- skice riječi (engl. WordSketches) sažetak gramatičkoga i kolokacijskoga opisa riječi utemeljen na gramatici skica
- Skoleordbog danski školski rječnik, pristup se plaća, namijenjen je učenicima osnovne škole, natuknice su obogaćene slikama i zvučnim zapisima
- specijalizirani korpus > specijalni korpus
- specijalni korpus (engl. specialized corpus) korpus koji (za razliku od općega korpusa) obuhvaća samo jedan jezični varijetet odabran po određenim kriterijima, npr. stručni korpusi (korpusi stručnih tekstova)
- SRL (semantic role labeling) > označivanje semantičkih uloga
- srWac (Srpski mrežni korpus) lematiziran i morfološki označen korpus srpskoga jezika; inačica 1.0. sadržava 894 milijuna pojavnica
- stablo parsema v. parsemsko stablo
- strojno učenje (engl. machine learning) učenje računala da izvrše automatske radnje te ih s vremenom usavršavaju na temelju unesenih podataka koje koriste za učenje njihova izvođenja
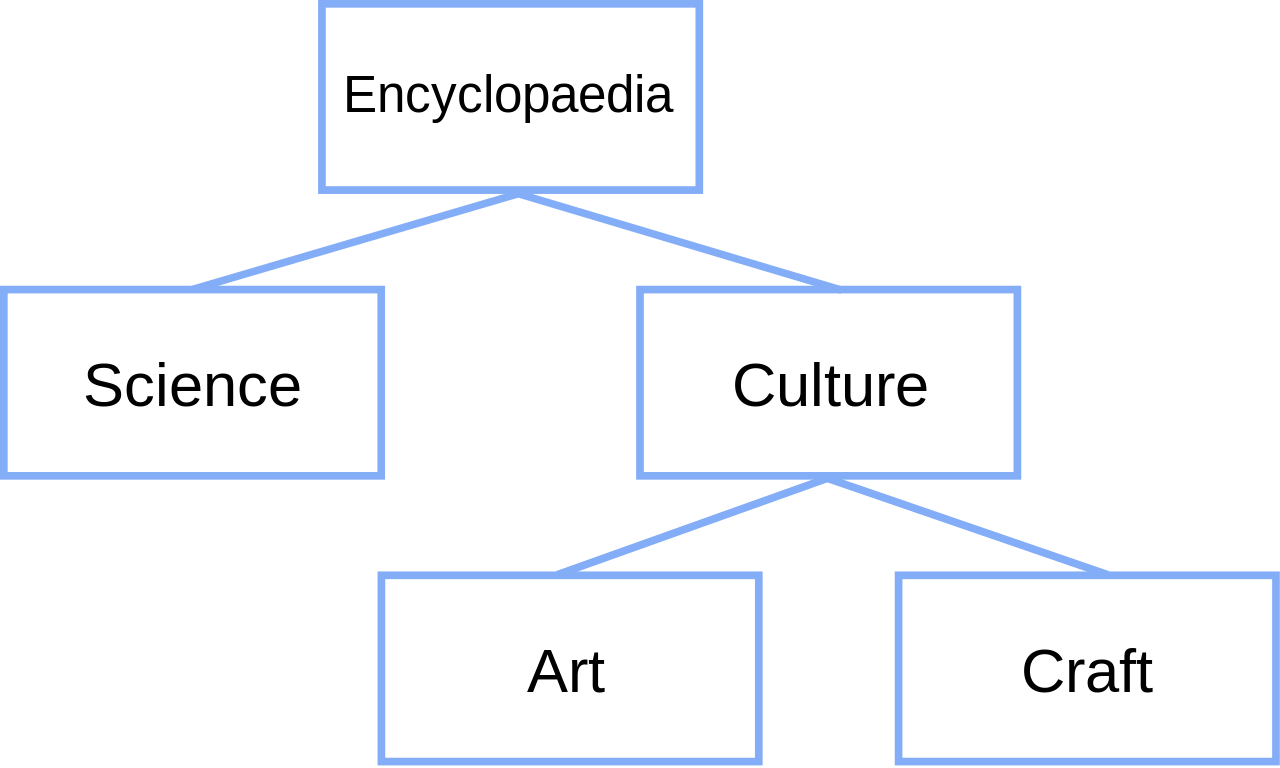
- struktura stabla (engl. T-structure, tree-structure) hijerarhijska struktura podataka u kojoj su elementi povezani s drugim elementima koji se mogu nalaziti iznad, ispod ili do njih; veze između elemenata zovu se grane; struktura podatka najčešće je hijerarhijski ustrojena od jednoga gornjeg elementa (korijena) koji se dalje dijeli na podelemente koji dalje mogu imaju svoje podelemente
- SyntagNet baza leksičko-semantičkih kombinacija dostupna na ELEXIS-ovim stranicama
- synset > sinonimni skup
- Svenska Akademiens ordbok povijesni rječnik koji opisuje švedski jezik od 1521. do današnjih dana, mrežna verzija tiskanoga rječnika koji izdaje Švedska akademija, a trenutačno obuhvaća 37 svezaka u kojima su obrađene natuknice a – vret
- Svenska Akademiens ordlista popis švedskih riječi s podatcima o njihovu pisanju, oblicima, izgovoru te osnovnim podatcima o značenju koji izdaje Švedska akademija
- Svensk ordbok jednojezični rječnik Švedske akademije dostupan na portalu svenska.se, koji okuplja jezične izvore Švedske akademije [doznaj više...]
- SW (Semantic Web) > semantička mreža
- Šolar korpus školskih pisanih uradaka učenika slovenskih osnovnih i srednjih škola nastalih 2009. – 2010.; korpus je nastao u okviru projekta Sporazumevanje v slovenskem jeziku
- T-structure (tree-strucutre) > struktura stabla
- Taalportaal (Jezični portal) jezični portal nizozemskoga, frizijskoga i afrikaansa, opsežan projekt u kojemu sudjeluju istraživači Instituta za nizozemski jezik, Sveučilišta u Leidenu, Frizijske akademije u Leeuwardenu te Meertensova instituta u Amsterdamu [doznaj više...]
- tag (engl. tag) 1. oznaka koja se pridružuje pojavnici u korpusu, 2. oznaka kojom se označuje da pojavnica pripada određenoj vrsti riječi
- tager (engl. tagger, POS tagger) dio programske podrške koji pridružuje identifikacijsku ili klasifikacijsku oznaku dijelovima teksta ili podatcima
- tagiranje (engl. tagging, POS tagging, part-of-speech tagging, POST) 1. označavanje pojavnica u tekstu (korpusu), 2. > gramatičko tagiranje
- tagirati (engl. to tag) 1. označiti/označavati pojavnice u tekstu (korpusu), 2. označiti/označavati riječ u tekstu (korpusu) kao pripadnicu određene vrste riječi, pridružiti/pridruživati oznake za vrstu riječi pojavnicama u korpusu, identificirati vrstu riječi i oblike pojedinih riječi
- TEI (Text Encoding Initiative) konzorcij koji razvija i održava standard za prikazivanje tekstova u digitalnome obliku; u njegovim smjernicama određene su metode kodiranja strojno čitljivih tekstova, stoga se primjenjuju u humanističkim i društvenim znanostima (a posebno u jezikoslovlju)
- Terminologie terminološki portal Ekspertnoga centra za nizozemsku terminologiju (Expertisecentrum Nederlandstalige Terminologie) [doznaj više...]
- tezaurus (engl. thesaurus) zbirka riječi prirodnoga jezika (općega i/ili stručnoga) s prikazom njihovih pojmovnih odnosa
- TickBox Lexicography SketchEngineov alat koji omogućuje da se primjeri pritiskom miša umeću iz skica riječi u program za obradu rječnika
- TLex (TshwaneLex) paket programskih aplikacija s velikim brojem funkcija koji služi za izradu rječnika
- treebank > banka stabala
- TshwaneLex v. TLex
- token > pojavnica
- umjetna inteligencija (engl. artificial intelligence) područje računalne znanosti koje se bavi izradom programa i sustava koji mogu automatski izvršavati zadatke za koje je potreban neki oblik inteligencije, tj. koji se mogu snalaziti u novim prilikama, učiti nove pojmove, donositi zaključke, razumjeti prirodni jezik, raspoznavati prizore i dr.
- univerzalna ovisnost (engl. universal dependencies) platforma za unakrižnu jezično konzistentnu gramatičku anotaciju koja omogućuje zajednički rad većega broja suradnika
- unutarrječničko povezivanje (engl. cross-referencing) povezivanje rječničkih članaka ili dijelova rječničkih članaka unutar rječnika s pomoću poveznica
- usporedni korpus (engl. parallel corpus) dvojezični ili višejezični korpus koji sadržava niz tekstova na dva ili više jezika; važan alat za istraživanje nazivlja,kontrastivnu jezikoslovnu analizu, definiranje prijevodnih ekvivalenata, sastavljanje dvojezičnih i višejezičnih rječnika
- upitni jezik (engl. query language) računalni jezik koji se upotrebljava za prikupljanje određenih podataka iz baze podatka ili informacijskoga sustava
- VerbAtlas semantički izvor za sveobuhvatno, i skalabilno označivanje uloga (Role Labeling) dostupan na ELEXIS-ovim stranicama
- vikifikacija (engl. wikification) prepoznavanje i povezivanje riječi u tekstu s postojećim mrežnim člancima na Wikipediji
- višerazinska anotacija (engl. multi-level annotation) anotacija koja obuhvaća više jezičnih razina
- višeslojna anotacija (engl. multi-layer annotation) > višerazinska anotacija
- vizualni rječnik (engl. visual dictionary) rječnik koji značenje riječi objašnjava slikama, koji sadržava ilustracije ili crteže
- WebAnno mrežni program za višeslojnu jezičnu anotaciju (morfološku, sintaktičku i semantičku); moguće odrediti i dodatni sloj za vlastite potrebe, koji ne mora biti jezični
- wikification v. vikifikacija
- word embedding tehnike u obradi prirodnog jezika u kojima se riječi ili izrazi prikazuju kao vektori realnih brojeva
- Wikifier mrežni servis koji obrađuje unesen ili učitan tekst tako što stvara mrežne poveznice na članke za Wikipediji za riječi koje se u njemu spominju (za jezik na kojemu je unesen i za još jedan jezik po izboru)
- Wiktionary Wikimedijin mrežni višejezični internetski suradnički projekt u okviru kojega se stvara rječnik slobodnoga sadržaja dostupan na više od 150 jezika; uključuje i hrvatski Wječnik
- Wiki-rječnik v. Wječnik
- Wječnik hrvatski internetski rječnik nastao u okviru projekta Wiktionary u okviru kojega se stvara rječnik slobodnoga sadržaja dostupan na više od 150 jezika
- WordNet velika mrežno dostupna rječnička baza engleskoga jezika; temelji se na okupljanju četiriju vrsta riječi (imenica, pridjeva, glagola i priloga) u skupine kognitivnih sinonima; struktura baze upućuje na odnose među riječima, i to uglavnom među riječima koje pripadaju istoj vrsti riječi (npr. hiperonimiju/hiponimiju, meronimiju, antonimiju itd.)
- Woordcombinaties (Sveze riječi) projekt u okviru kojega se izrađuje kolokacijska baza nizozemskoga jezika [doznaj više...]
- WordSketches > skice riječi
- xml (EXtensible Markup Language) jednostavno čitljiv standardizirani jezik za označivanje podataka
- ZDL (Zentrum für digitale Lexikographie der deutschen Sprache)
- Zentrum für digitale Lexikographie der deutschen Sprache (ZDL, Centar za digitalnu leksikografiju njemačkoga jezika) projekt pokrenut 2019. godine s ciljem izrade digitalnoga informacijskog sustava koji bi iscrpno i pouzdano opisivao povijesni i suvremeni leksik njemačkoga jezika; suorganizatori su njemačke akademije znanosti u Berlinu, Göttingenu, Leipzigu i Mainzu